

DOM 模型
DOM(Document Object Model)定义的是一组与平台、语言无关的接口,该接口允许编程语言动态访问和更改结构化文档。W3C标准化组织定义一系列 DOM 接口,随着时间的推移,目前已经形成了三个演进的标准:DOM Level 1、DOM Level 2、DOM Level 3,每个 Level 都是在原有的基础上增加新的接口以加强功能。各个阶段比较重要的功能如下:
- Level 1
- Core: 支持 XML 文档
- HTML: 在 Core 的基础上对 HTML 文档进行访问,把 HTML 中的内容定义为文档(Document)、节点(Node)、属性(Attribute)、元素(Element)、文本(Text)等。
- Level 2
- Core: 扩展 Level 1 Core,如新增 getElemntById
- Events: 引入了对 DOM 事件的处理,支持 EventTarget、Mouse 事件等接口,但仍然不支持键盘事件,这个事件在 DOM Level 3才被加入
- HTML: 扩充 Level 1 HTML,允许动态访问和修改 HTML 文档
- Level 3
- Core: 新增 adoptNode 和 textContent
- Events: 主要加入了对键盘的支持
由于 DOM 的定义是与语言无关的,所以标准中所有这些都是接口,它支持不同类型的语言,例如 C++、Java 或者 Javascript。
HTML 解释器
解释过程
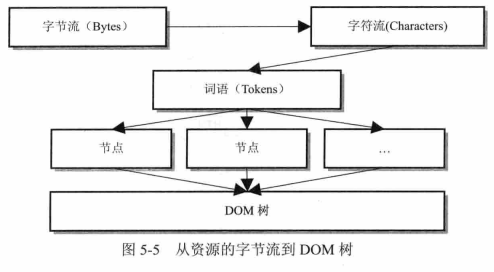
在 Webkit 中,首先对字节流解码获得字符流,如果 HTML 网页中设置了编码格式,则 Webkit 会使用相应的解码器来将字节流转换成特定格式的字符串。然后通过词法解析器解释成词语(Tokens),之后经过语法分析器构建成节点,最后这些节点被组建成一棵 DOM 树。
节点到 DOM 树
Webkit 在解析 HTML 文档时使用了栈结构,例如一个片段“<body><div><img></img></div></body>”,当解释到 img 元素的开始标记时,栈中的元素就是 body、div、img,当遇到 img 的结束标记时,img 退栈,img 是 div 的子女;当遇到 div 的结束标记时,div 退栈,表明 div 和它的子女都已经处理完,依次类推。
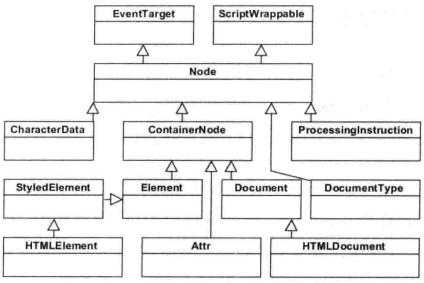
同 DOM 标准一样,一切的基类都是 Node 类。在 Webkit 中,DOM 中的接口 Interface 对应于 C++ 类,Node 类是其他类的基类。
Webkit 中节点相关的类如下:
网页基础设施
Webkit 中的基础设施类时被各个移植所共享的,移植通过调用这些类来进行布局、渲染等操作,下图描述了 Chrominum 是如何调用 Webkit 接口的。
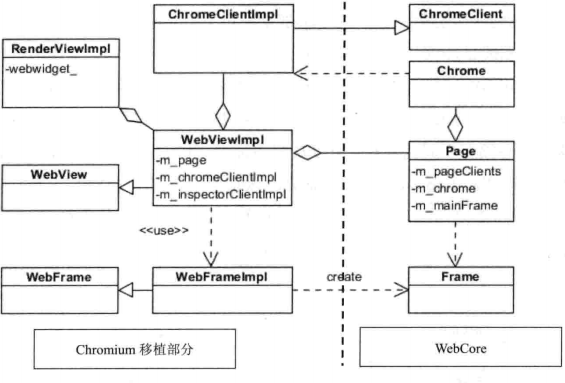
图中左边是 Webkit 的 Chrominum 移植实现使用的接口类,WebView 和 WebFrame 类分别表示网页和网页框,WebViewImpl 和 WebFrameImpl 是 Chrominum 实现的子类,它们负责使用 Page、Frame 等 WebCore 中的类来支持两个对外类的接口。Page类是 Webkit 内部用来表示网页的类,WebView 是 Webkit 对外表示网页的类,Frame 类和 WebFrame 类也是这样的关系。
这里的 Chrome 是 Webkit 的一个类,表示的是网页所绘制的与实现相关的一个窗口。其具备获取各个平台资源的能力,例如 Webkit 可以调用 Chrome 类来创建一个新窗口(可以是 JavaScript 的 alert 窗口)。
线程化的解释器
在 Webkit 中,网络资源的字节流自 IO 线程传递给渲染线程之后,后面的解释、布局、和渲染工作基本上都是在该线程,也就是渲染线程完成的。因为 DOM 树只能在渲染线程上创建和访问,也就是说构建 DOM 树的过程只能在渲染线程中进行。但是,从字符串到词语这个阶段可以交给单独的线程来做。在Webkit 的 Chrominum 移植中就是将这一过程放在在单独的线程中,在该线程中将字符串解释成词语之后,Webkit 会分批次地将结果传递给渲染线程。
JavaScript 的执行
因为 JavaScript 的执行可能会调用例如“document.write()”来修改文档结构,所以 JavaScript 代码的执行会阻碍后面节点的创建,同时也会阻碍后面的资源的下载,为了解决这个问题,Webkit 使用预扫描和预加载机制来实现资源的并发下载而不被 JavaScript 的执行而阻碍。
具体的做法是,当遇到需要执行 JavaScript 的时候,Webkit 先暂停当前 JavaScript 代码的执行,使用预先扫描器 HTMLpreLoadScanner 类来扫描后面的词语。如果 Webkit 发现它们需要使用其他资源,那么使用预资源加载器 HTMLResourcePreloader 类来发送请求,在这之后,才执行 JavaScript 的代码。预先扫描器本身并不创建节点对象,也不会构建 DOM 树,所以速度比较快。不过,并不是所有渲染引擎都像 Webkit 这样处理,所以开发网页时尽量把 script 标签放到最后。
DOM 的事件机制
事件的工作过程
事件在工作过程中使用两个主体,第一个是事件(Event),第二个是事件目标(EventTarget)。当渲染引擎接收到一个事件的时候,它会通过 HitTest(Webkit 中的一种检查触发事件在哪个区域的算法)检查哪个元素是直接的事件目标。然后,事件会经过捕获和冒泡两个过程。
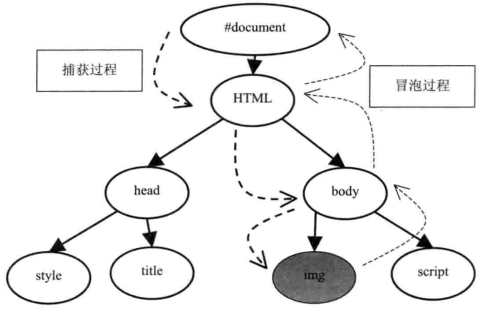
捕获过程是自顶向下的,中间的元素可以捕获该事件,通过事件的“stopPropagation”函数可以阻止事件的向下传递。事件的冒泡过程是从下向上的,在冒泡的过程中,中间的元素也可以响应该事件,同样,通过事件的“stopPropagation”函数可以阻止事件的向上传递。
Webkit 的事件处理机制
基于 Webkit 的浏览器事件处理过程,首先是做 HitTest,查找事件发生的元素,检测该元素有无监听者。如果发现有监听者,它需要将这些事件传递给 Webkit,Webkit 实际上最后调用 JavaScript 引擎来触发监听者函数。
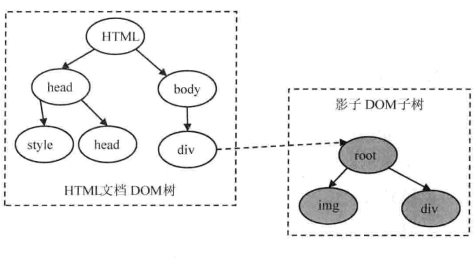
影子 DOM
影子 DOM 的规范草案能够使得一些 DOM 节点在特定范围内可见,而在网页的 DOM 树中却不可见,但是网页渲染的结果中包含了这些节点,这就使得封装变得容易很多。通常的接口是不能直接访问到影子 DOM 子树中的节点的,JavaScript 代码只能通过特殊的接口方式。其实,video 等有控制界面的元素就是使用了影子 DOM 的思想。
对于影子 DOM 子树,事件目标其实就是包含影子 DOM 子树的节点对象。事件捕获的逻辑没有发生变化,在影子 DOM 子树内也会继续传递。当影子 DOM 子树中的事件向上冒泡的时候,Webkit 会同时向整个文档的 DOM 上传递该事件,以避免一些奇怪的行为。
使用影子 DOM
