

Webkit 资源加载机制
资源
HTML 支持的资源主要包括以下类型:
- HTML文档
- JavaScript 文件
- CSS 样式文件
- 图片
- SVG
- CSS Shader
- 视频、音频和字幕:多媒体资源及支持音视频的字幕文件(TextTrack)
- 字体文件
- XSL 样式表:使用 XSLT 语言编写的 XSLT 代码文件
上面这些资源在 Webkit 中均有不同的类来表示它们,它们的公共基类是 CachedResource。HTML 对应的资源类型叫 CachedRawResource 类。
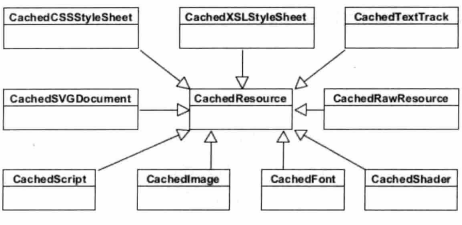
资源类的前面一般以“Cached”开头,所有资源在请求之前都会先获取缓存中的信息,以决定是否向服务器提出资源请求。
资源缓存
当 Webkit 需要请求资源的时候,先从资源池中查找是否存在相应的资源。如果有,Webkit 则取出以便使用;如过没有,Webkit 创建一个新的 CachedResource 子类的对象,并发送真正的请求给服务器,Webkit 收到资源后将其设置到该资源类的对象中去,以便于缓存后下次使用。这里的缓存指的时是内存缓存,而不同于后面在网络栈部分的磁盘缓存。
Webkit 从资源池中查找资源的关键字是 URL,所以即使两个资源内存完全一样,但只要 URL 不同,也被认为是两个不同的资源。
资源加载器
Webkit 总共三种类型的资源加载器:
- 针对每种资源类型的特定加载器:Fontloader、ImageLoader等;
- 缓存机制的资源加载器:CachedResourceLoader,所有特定加载器都会先通过缓存机制的资源加载器来查找是否有缓存资源;
- 通用资源加载器:ResourceLoader,
加载过程
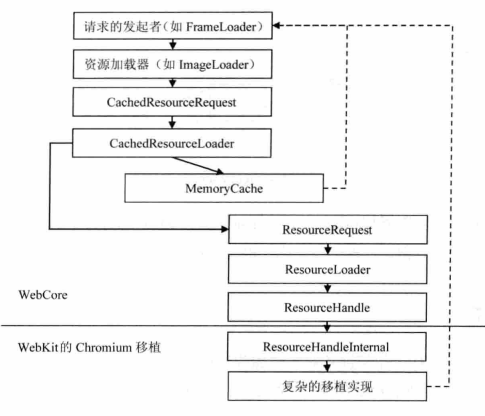
资源的加载通常是异步执行的,也就是资源的加载不会阻碍当前 Webkit 的渲染过程,例如图片、CSS 文件。当然,也有些资源会阻碍主线程的渲染过程,例如 JavaScript 代码文件。当遇到这中情况时,Webkit 会启动另外一个线程去遍历后面的 HTML 网页,收集需要的资源 URL,然后发送请求,这样就可以避免被阻碍。与此同时,Webkit 能够并发下载这些资源,甚至并发下载 JavaScript 代码资源。
资源的生命周期
内存中资源池是有限的,Webkit 采用 LRU(Least Recent Used 最近最少使用)算法来替换其中的旧资源,加入新的资源。
资源缓存实践
默认情况下,浏览器是会启动资源缓存的,当我们使用调试工具开启 Disable cache 后,则浏览器在请求资源时会加上 “Pragma: no-cache” 字段,加载机制检查到该字段后会直接发起网络请求,而不会再检查缓存池,并且会将请求中的 If-Modified-since、If-None-Match 等和缓存生命周期相关的字段去掉。
Chrominum 多进程资源加载
在 Chrominum 中,获取资源的方式是利用多进程的资源加载架构。
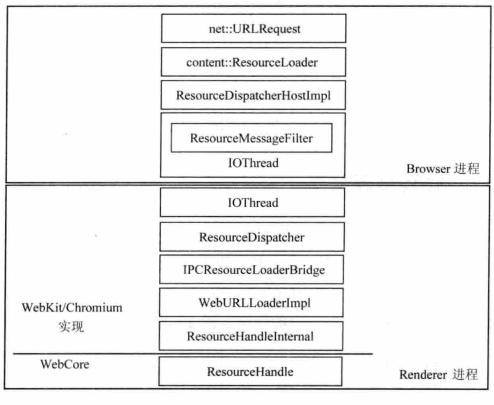
在 ResourceHandle 类之下的部分,是不同移植对获取资源的不同实现。Render 进程的资源获取世纪上是通过进程间通信将任务交给 Browser 进程来完成,Browser 进程有权限从网络或者本地获取资源。从网络或者本地文件读取信息的是 URLRequest 类,它承担了建立网络连接、发送请求数据和接收回复数据的任务。
因为每个 Render 进程某段时间内可能有多个请求,同时还有多个 Render 进程,Browser 进程需要处理大量的资源请求,这就需要一个处理这些请求的调度器,这就是 Chrominum 中的 ResourceScheduler。ResourceScheduler 类管理的对象就是上图中的 URLRequest 对象。ResourceScheduler 类根据 URLRequest 的标记和优先级来调度 URLRequest 对象,每个 URLRequest 对象都有一个 ChildId 和 RouteId 来标记属于哪个 Render 进程。ResourceScheduler 类中有一个哈希表,该表按照进程来组织 URLRequest 对象。对于以下类型的网络请求,将立即被 Chrominum 发出:
- 高优先级的请求
- 同步请求
- 具有 SPDY 能力的服务器
网络栈
Webkit 网络设施
Webkit 从网络加载资源其实是由各个移植来实现的,所以 WebCore 其实并没有什么特别的基础设施,每个移植的网络实现是非常不一样的。
Chrominum 网络栈

结构
Webkit 使用 HttpTransactionFactory 对象创建一个 HttpTransaction 对象来表示开启一个 HTTP 连接的事务。通常情况下,HttpTransaction 对象对应的是一个它的子类 HttpCache 对象。HttpCache 类使用本地磁盘缓存机制,如果该请求对应的回复已经在磁盘缓存中,那么 Chrominum 无需再建立 HttpTransaction 来发起连接,而是直接从磁盘中获取即可。如果磁盘缓存中没有该 URL 的缓存,同时如果该 URL 请求对应的 HttpTransaction 已经建立,那么只要等待它的回复即可。当这些条件都不满足的时候,Chrominum 才会真正创建 HttpTransaction 对象。
本地磁盘缓存中的文件在磁盘空间足够的情况下是有生命周期的,生命周期主要依据 Http 请求返回的字段来设置,具体可参考 http 缓存
域名解析
Chrominum 中使用 HostResolverImpl 类来解析域名。为了考虑效率,使用 HostCache 类来保存解析后的域名,最多时会有多达1000个的域名和地址映射关系会被存储起来。可以在 Chrome 浏览器地址栏中输入“chrome://net-internals/#dns”来查看。
磁盘本地缓存
特性
- 磁盘空间有限,需要有相应的机制来移除合适的缓存资源,以便加入新的资源
- 能确保在浏览器崩溃时不破坏磁盘文件
- 支持同步和异步两种方式访问磁盘
- 磁盘不支持多线程访问,需要把所有的磁盘缓存操作放入单独一个线程
结构
Webkit 磁盘缓存机制对外接口主要有两个类:Backend 和 Entry。Backend 类表示整个磁盘缓存,是所有针对磁盘缓存操作的主入口,表示的是一个缓存表。Entry 类指的是表中的项。每个项由关键字来唯一确定,这个关键字就是资源的 URL。可以通过“chrome://view-http-cache/”来查看这些项。
Chrominum 至少需要一个索引文件和四个数据文件(数据文件名形如“data_x”)。当资源文件大小超过一定值的时候,Chrominum 会建立单独的文件来保存他们(文件名形如“f_xxxxx”),而不是将它们放入上面的4个数据文件中。
如果手动删除cache文件夹,chrome 浏览器启动时会重新创建 cache 文件夹,并生成四个 data_x 文件和一个 index索引文件。
Cookie 机制
一个网页的 Cookie 只能被该网页(或者说是该域的网页)访问。根据 Cookie 的时效性可以将 Cookie 分成两种类型,第一种是会话型 Cookie(Session Cookie),这些 Cookie 只是保存在内存中,当浏览器退出的时候即清除这些 Cookie。如果 Cookie 没有设置失效时间,就是会话型 Cookie。第二中是持续型 Cookie(Persistent Cookie),也就是当浏览器退出的时候,仍然保留 Cookie 的内容。该类型的 Cookie 有一个有效期,在有效期内,每次访问该 Cookie 所属域的时候,都需要将该 Cookie 发送个服务器,这样服务器就能够追踪用户的行为。
高性能网络栈
DNS 预取和 TCP 预连接(Preconnect)
依次 DNS 查询的平均时间大概是 60-120ms,而 TCP 的三次握手时间大概也是几十毫秒。为了有效的减少这段时间,Chrominum 使用 “Predictor”机制来实现 DNS 预取和 TCP 预连接。
DNS 预取技术主要思想是利用现有的 DNS 机制,提前解析网页中可能的网络连接。具体来讲,当用户正在浏览当前网页的时候,Chrominum 提取网页中的超链接,将域名提取出来,利用比较少的 CPU 和网络带宽来解析这些域名或 IP 地址,这样一来,用户根本感觉不到这一过程。
DNS 预取技术不是使用前面提到的 Chrominum 网络栈,而是直接利用系统的域名解析机制,所以它不会阻碍当前网络栈的工作。而且 DNS 预取技术针对多个域名采取并行处理的方式,每个域名的解析须由新开启的一个线程来处理,结束后此线程即退出。
在HTML文档中,可以显示指定预取哪些域名,具体做法是添加特殊的link标签:<link rel="dns-prefetch" href="https://www.baidu.com">。另外,当用户在地址中输入地址后,在用户敲击回去建之前,Chrominum 已经开始使用 DNS 预取技术解析该域名了。可以通过“chrome://dns/”查看 Chrominum 的 DNS 预取的域名。
Chrominum 使用追踪技术来预测用户接下来将点击什么超链接,当有足够的把把握时,就可以预先建立 TCP 连接。同 DNS 预取技术一样,追踪技术不仅应用于网页中的超链接,当用户在地址栏中输入地址,在用户敲下回车键之前,Chrominum 可能就已经开始尝试建立 TCP 连接了。
HTTP 管线化(Pipelining)
HTTP1.1 开始增加了管线化技术。Chrominum 当然也支持这一技术,但它需要服务器的支持,两者配合才能实现 HTTP 管线化。
HTTP 管线化技术允许多个 http 请求通过一个套接字同时被输出 ,而不用等待相应的响应。然后请求者就会等待各自的响应,这些响应是按照之前请求的顺序依次到达。(所有请求保持一个FIFO的队列,同时,服务器端返回这些请求的响应时也是按照FIFO的顺序)
管线化技术需要通过持久连接来完成,并且只有 GET 和 HEAD 等请求可以进行管线化,使用场景有很大的限制。
SPDY
SPDY 是一种新的会话层协议,在 HTTP2.0 的草案中被引入,被定义在 HTTP 协议和 TCP 协议之间。
SPDY 协议的核心思想是多路复用,仅使用一个连接来传输一个网页中众多资源。它本质上并没有改变 HTTP 协议,只是将 HTTP 协议头通过 SPDY 来封装和传输。数据传输方式也是使用 TCP/IP 来传输。所以,SPDY 协议相对来说比较容易部署,服务器只需要插入 SPDY 协议的解释层,从 SPDY 的消息头中获取各个资源的 HTTP 头即可。其次,SPDY 协议必须建立在 SSL 层之上。
SPDY 特征如下:
- 对于一条 SPDY 连接,并发的发起多少request没有任何限制
- 根据请求的特性和优先级,SPDY 可以调整这些资源请求的优先级,例如 Javascript 资源的优先级很高,服务器可以优先传输回复该类型的请求(这与管线化技术的 FIFO 不同)
- 对请求头使用压缩技术
- 支持 SPDY 协议的服务器在发送网页内容时,可以尝试发送一些信息给浏览器,告诉浏览器后面可能需要哪些资源,浏览器可以提前知道并决定是否需要下载。更极端的情况是,服务器可以主动发送资源。
Webkit 内存缓存与磁盘缓存完整流程
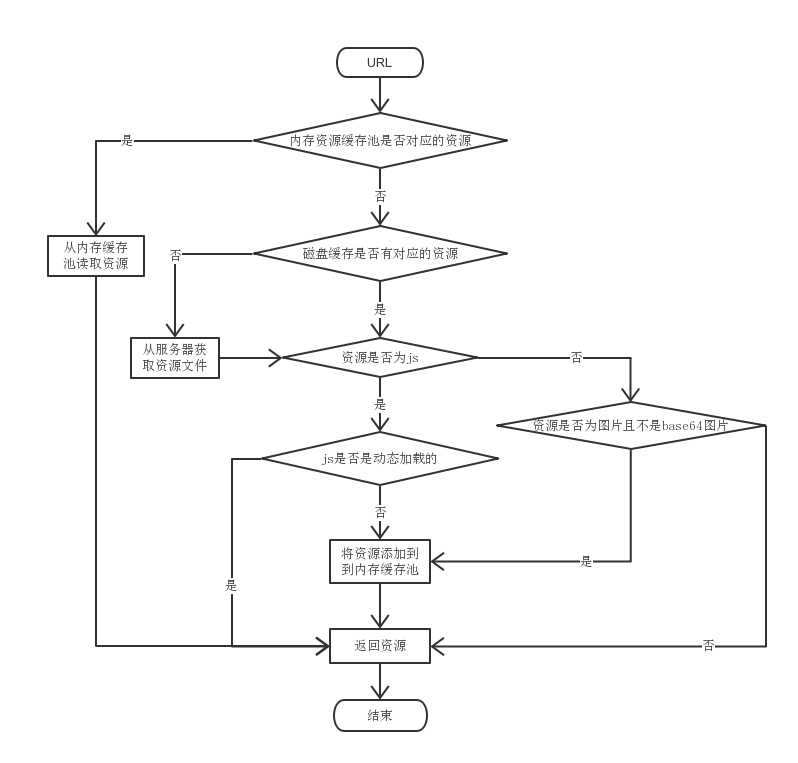
第一次访问网页(这里以 https://www.baidu.com 为例),所有资源将从服务器获取:
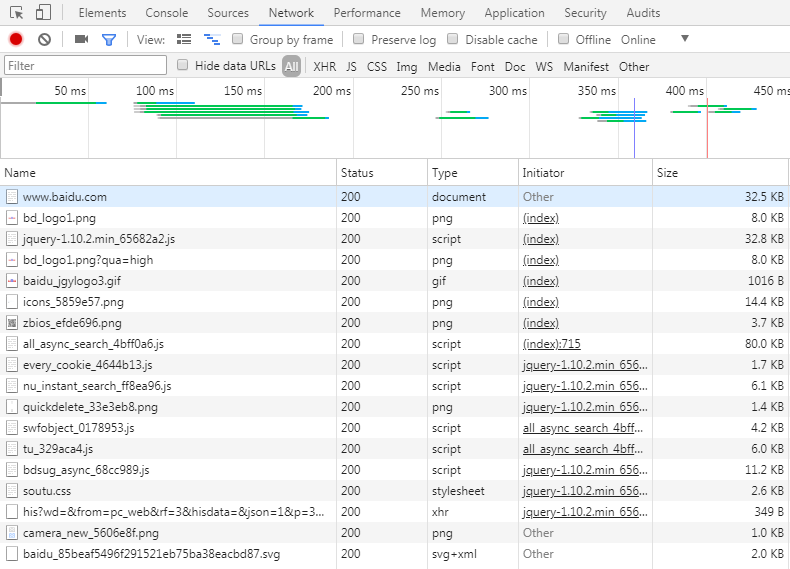
此时,理论上所有从服务器请求到的资源文件已经都存储到磁盘上了,并且满足上图条件中 JavaScript 文件和图片文件将保存到内存缓存池。
接着刷新网页:
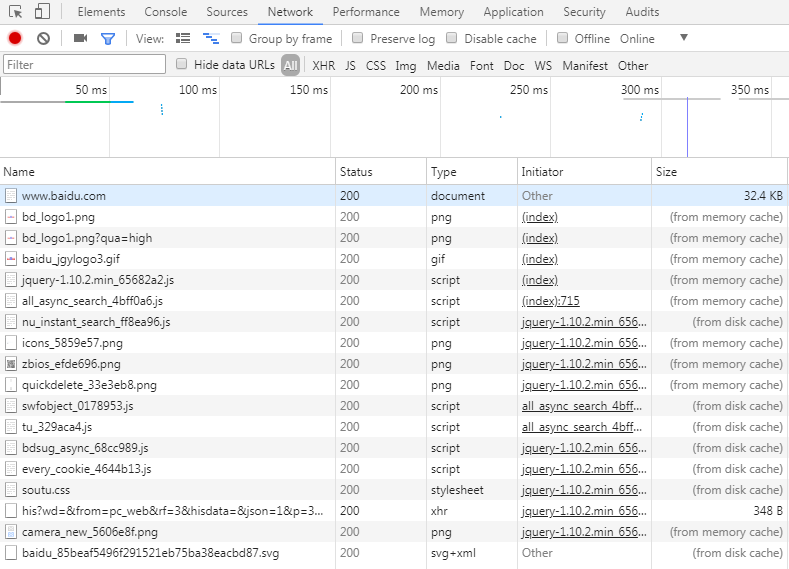
可以看到非动态加载的 JavaScript 文件和图片文件都时从内存缓存池中获取(from memory cache),而其他资源除了 xhr 请求,都是从磁盘缓存获取(form disc chace)。
最后,关闭网页,重新打开网页:
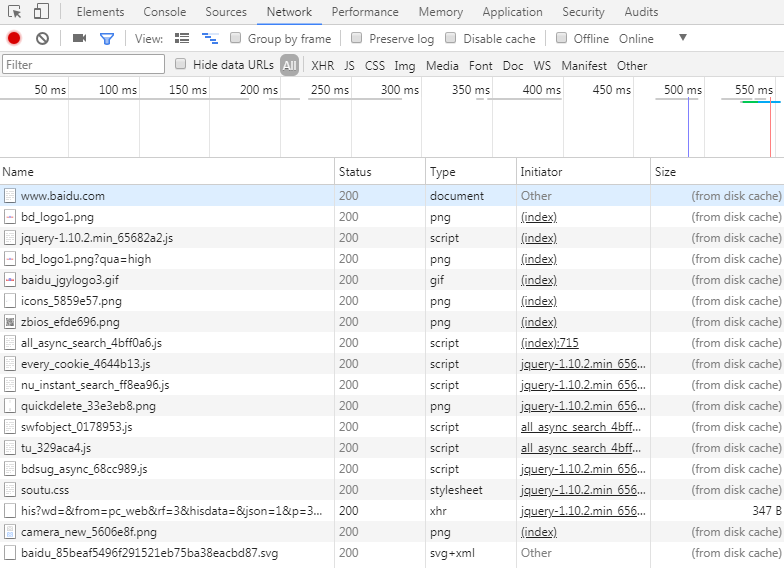
此时,所有的资源第一次都将从磁盘缓存获取。